The
Framework is a 13.5" laptop body with swappable parts, which
makes it somewhat future-proof and certainly easily repairable,
scoring an "exceedingly rare"
10/10 score from ifixit.com.
There are two generations of the laptop's main board (both compatible
with the same body): the Intel 11th and 12th gen chipsets.
I have received my Framework, 12th generation "DIY", device in late
September 2022 and will update this page as I go along in the process
of ordering, burning-in, setting up and using the device over the
years.
Overall, the Framework is a good laptop. I like the keyboard, the
touch pad, the expansion cards. Clearly there's been some good work
done on industrial design, and it's the most repairable laptop I've
had in years. Time will tell, but it looks sturdy enough to survive me
many years as well.
This is also one of the most powerful devices I ever lay my hands
on. I have managed, remotely, more powerful servers, but this is the
fastest computer I have ever owned, and it fits in this tiny case. It
is an amazing machine.
On the downside, there's a bit of proprietary firmware required (WiFi,
Bluetooth, some graphics) and the Framework ships with a proprietary
BIOS, with currently
no Coreboot support. Expect to need the
latest kernel, firmware, and hacking around a bunch of things to get
resolution and keybindings working right.
Like others, I have first found significant power management issues,
but many issues can actually be solved with some configuration. Some
of the expansion ports (HDMI, DP, MicroSD, and SSD) use power when
idle, so don't expect week-long suspend, or "full day" battery while
those are plugged in.
Finally, the expansion ports are nice, but there's only four of
them. If you plan to have a two-monitor setup, you're likely going to
need a dock.
Read on for the detailed review. For context, I'm moving from the
Purism Librem 13v4 because it
basically exploded on me. I
had, in the meantime, reverted back to an old ThinkPad X220, so I
sometimes compare the Framework with that venerable laptop as well.
This blog post has been maturing for
months now. It started in
September 2022 and I declared it completed in March 2023. It's the
longest single article on this entire website, currently clocking at
about 13,000 words. It will take an average reader a full hour to go
through this thing, so I don't expect anyone to actually
do
that. This introduction should be good enough for most people, read
the first section if you intend to actually buy a Framework. Jump
around the table of contents as you see fit for after you did buy the
laptop, as it might include some crucial hints on how to make it work
best for you, especially on (Debian) Linux.
Advice for buyers
Those are things I wish I would have known before buying:
- consider buying 4 USB-C expansion cards, or at least a mix of 4
USB-A or USB-C cards, as they use less power than other cards and
you do want to fill those expansion slots otherwise they snag
around and feel insecure
- you will likely need a dock or at least a USB hub if you want a
two-monitor setup, otherwise you'll run out of ports
- you have to do some serious tuning to get proper (10h+ idle, 10
days suspend) power savings
- in particular, beware that the HDMI, DisplayPort and
particularly the SSD and MicroSD cards take a significant amount
power, even when sleeping, up to 2-6W for the latter two
- beware that the MicroSD card is what it says: Micro, normal SD
cards won't fit, and while there might be full sized one
eventually, it's currently only at the prototyping stage
- the Framework monitor has an unusual aspect ratio (3:2): I
like it (and it matches classic and digital photography aspect
ratio), but it might surprise you
Current status
I have the framework! It's setup with a fresh new Debian bookworm
installation. I've ran through a large number of tests and burn in.
I have decided to use the Framework as my daily driver, and had to buy
a USB-C dock to get my two monitors
connected, which was own adventure.
Update: Framework just (2023-03-23) just announced a whole bunch of
new stuff:
The recording is available in this video and it's not your
typical keynote. It starts ~25 minutes late, audio is crap, lightning
and camera are crap, clapping seems to be from whatever staff they
managed to get together in a room, decor is bizarre, colors are
shit. It's amazing.
Specifications
Those are the specifications of the 12th gen, in general terms. Your
build will of course vary according to your needs.
- CPU: i5-1240P, i7-1260P, or i7-1280P (Up to 4.4-4.8 GHz, 4+8
cores), Iris Xe graphics
- Storage: 250-4000GB NVMe (or bring your own)
- Memory: 8-64GB DDR4-3200 (or bring your own)
- WiFi 6e (AX210, vPro optional, or bring your own)
- 296.63mm X 228.98mm X 15.85mm, 1.3Kg
- 13.5" display, 3:2 ratio, 2256px X 1504px, 100% sRGB, >400 nit
- 4 x USB-C user-selectable expansion ports, including
- USB-C
- USB-A
- HDMI
- DP
- Ethernet
- MicroSD
- 250-1000GB SSD
- 3.5mm combo headphone jack
- Kill switches for microphone and camera
- Battery: 55Wh
- Camera: 1080p 60fps
- Biometrics: Fingerprint Reader
- Backlit keyboard
- Power Adapter: 60W USB-C (or bring your own)
- ships with a screwdriver/spludger
- 1 year warranty
- base price: 1000$CAD, but doesn't give you much, typical builds
around 1500-2000$CAD
Actual build
This is the actual build I ordered. Amounts in CAD. (1CAD =
~0.75EUR/USD.)
Base configuration
- CPU: Intel Core i5-1240P (AKA Alder Lake P 8 4.4GHz
P-threads, 8 3.2GHz E-threads, 16 total, 28-64W), 1079$
- Memory: 16GB (1 x 16GB) DDR4-3200, 104$
Customization
- Keyboard: US English, included
Expansion Cards
- 2 USB-C $24
- 3 USB-A $36
- 2 HDMI $50
- 1 DP $50
- 1 MicroSD $25
- 1 Storage 1TB $199
- Sub-total: 384$
Accessories
- Power Adapter - US/Canada $64.00
Total
- Before tax: 1606$
- After tax and duties: 1847$
- Free shipping
Quick evaluation
This is basically the TL;DR: here, just focusing on broad pros/cons of
the laptop.
Pros
- easily repairable (complete with QR codes pointing to repair
guides!), the 11th gen received a 10/10 score from
ifixit.com, which they call "exceedingly rare", the 12th gen
has a similar hardware design and would probably rate similarly
- replaceable motherboard!!! can be reused as a NUC-like device, with a
3d-printed case, 12th gen board can be bought standalone and
retrofitted into an 11th gen case
- not a passing fad: they made a first laptop with the 11th gen Intel
chipset in 2021, and a second motherboard with the 12th Intel
chipset in 2022
- four modular USB-C ports which can fit HDMI, USB-C (pass-through,
can provide power on both sides), USB-A, DisplayPort, MicroSD,
external storage (250GB, 1TB), active modding community
- nice power led indicating power level (charging, charged, etc) when
plugged
- test account on fwupd.org, "expressed interest to port to
coreboot" (according to the Fedora developer) and are testing
firmware updates over fwupd, present on LVFS testing, but
including for the 12th gen, latest BIOS (3.06) was shipped
through LVFS
- excellent documentation of the (proprietary) BIOS
- explicit Linux support with install guides, although you'll
have to live with a bit of proprietary firmware, and not everything
works correctly
- the 11th gen had good reviews: Ars Technica, Fedora
developer, iFixit teardown, phoronix, amazing
keyboard and touch pad, according to Linux After Dark, most
exciting laptops I've ever broken (Cory Doctorow) ; more
critical review from an OpenBSD developer
- the EC (Embedded Controller) is open source so of course
people are hacking at it, some documentation on what's
possible (e.g. changing LED colors, fan curves, etc), see
also
Cons
- the 11th gen is out of stock, except for the higher-end CPUs, which
are much less affordable (700$+)
- the 12th gen has compatibility issues with Debian, followup in the
DebianOn page, but basically: brightness hotkeys, power
management, wifi, the webcam is okay even though the
chipset is the infamous alder lake because it does not have
the fancy camera; most issues currently seem solvable, and
upstream is working with mainline to get their shit working
- 12th gen might have issues with thunderbolt docks
they used to have some difficulty keeping up with the orders: first
two batches shipped, third batch sold out, fourth batch should have
shipped  in October 2021. they generally seem to keep up with
shipping. update (august 2022): they rolled out a second line of
laptops (12th gen), first batch shipped, second batch shipped
late, September 2022 batch was generally on time, see this
spreadsheet for a crowdsourced effort to track those
in October 2021. they generally seem to keep up with
shipping. update (august 2022): they rolled out a second line of
laptops (12th gen), first batch shipped, second batch shipped
late, September 2022 batch was generally on time, see this
spreadsheet for a crowdsourced effort to track those
supply chain issues seem to be under control as of early 2023. I
got the Ethernet expansion card shipped within a week.- compared to my previous laptop (Purism Librem
13v4), it feels strangely
bulkier and heavier; it's actually lighter than the purism (1.3kg
vs 1.4kg) and thinner (15.85mm vs 18mm) but the design of the
Purism laptop (tapered edges) makes it feel thinner
- no space for a 2.5" drive
rather bright LED around power button, but can be dimmed in the
BIOS (not low enough to my taste) I got used to it- fan quiet when idle, but can be noisy when running, for example if
you max a CPU for a while
- battery described as "mediocre" by Ars Technica (above), confirmed
poor in my tests (see below)
no RJ-45 port, and attempts at designing ones are failing
because the modular plugs are too thin to fit (according to Linux
After Dark), so unlikely to have one in the future
Update: they cracked that nut and ship an 2.5 gbps Ethernet
expansion card with a realtek chipset, without any
firmware blob 
- a bit pricey for the performance, especially when compared to the
competition (e.g. Dell XPS, Apple M1)
- 12th gen Intel has glitchy graphics, seems like Intel hasn't fully
landed proper Linux support for that chipset yet
Initial hardware setup
A breeze.
Accessing the board
The internals are accessed through five TorX screws, but there's a nice
screwdriver/spudger that works well enough. The screws actually hold in
place so you can't even lose them.
The first setup is a bit counter-intuitive coming from the Librem
laptop, as I expected the back cover to lift and give me access to the
internals. But instead the screws is release the keyboard and touch
pad assembly, so you actually need to flip the laptop back upright and
lift the assembly off to get access to the internals. Kind of
scary.
I also actually unplugged a connector in lifting the assembly because
I lifted it towards the monitor, while you actually need to lift it
to the right. Thankfully, the connector didn't break, it just
snapped off and I could plug it back in, no harm done.
Once there, everything is well indicated, with QR codes all over the
place supposedly leading to online instructions.
Bad QR codes
Unfortunately, the QR codes I tested (in the expansion card slot, the
memory slot and CPU slots) did not actually work so I wonder how
useful those actually are.
After all, they need to point to something and that means a URL, a
running website that will answer those requests forever. I bet those
will break sooner than later and in fact, as far as I can tell, they
just don't work at all. I prefer the approach taken by the MNT reform
here which designed (with the 100 rabbits folks) an actual paper
handbook (PDF).
The first QR code that's immediately visible from the back of the
laptop, in an expansion cord slot, is a 404. It seems to be some
serial number URL, but I can't actually tell because, well, the page
is a 404.
I was expecting that bar code to lead me to an introduction page,
something like "how to setup your Framework laptop". Support actually
confirmed that it should point a quickstart guide. But in a
bizarre twist, they somehow sent me the URL with the plus (+) signs
escaped, like this:
https://guides.frame.work/Guide/Framework\+Laptop\+DIY\+Edition\+Quick\+Start\+Guide/57
... which Firefox immediately transforms in:
https://guides.frame.work/Guide/Framework/+Laptop/+DIY/+Edition/+Quick/+Start/+Guide/57
I'm puzzled as to why they would send the URL that way, the proper URL
is of course:
https://guides.frame.work/Guide/Framework+Laptop+DIY+Edition+Quick+Start+Guide/57
(They have also "let the team know about this for feedback and help
resolve the problem with the link" which is a support code word for
"ha-ha! nope! not my problem right now!" Trust me, I know, my own
code word is "can you please make a ticket?")
Seating disks and memory
The "DIY" kit doesn't actually have that much of a setup. If you
bought RAM, it's shipped outside the laptop in a little plastic case,
so you just seat it in as usual.
Then you insert your NVMe drive, and, if that's your fancy, you also
install your own mPCI WiFi card. If you ordered one (which was my
case), it's pre-installed.
Closing the laptop is also kind of amazing, because the keyboard
assembly snaps into place with magnets. I have actually used the
laptop with the keyboard unscrewed as I was putting the drives in and
out, and it actually works fine (and will probably void your warranty,
so don't do that). (But you can.) (But don't, really.)
Hardware review
Keyboard and touch pad
The keyboard feels nice, for a laptop. I'm used to mechanical keyboard
and I'm rather violent with those poor things. Yet the key travel is
nice and it's clickety enough that I don't feel too disoriented.
At first, I felt the keyboard as being more laggy than my normal
workstation setup, but it turned out this was a graphics driver
issues. After enabling a composition manager, everything feels snappy.
The touch pad feels good. The double-finger scroll works well enough,
and I don't have to wonder too much where the middle button is, it
just works.
Taps don't work, out of the box: that needs to be enabled in Xorg,
with something like this:
cat > /etc/X11/xorg.conf.d/40-libinput.conf <<EOF
Section "InputClass"
Identifier "libinput touch pad catchall"
MatchIsTouchpad "on"
MatchDevicePath "/dev/input/event*"
Driver "libinput"
Option "Tapping" "on"
Option "TappingButtonMap" "lmr"
EndSection
EOF
But be aware that once you enable that tapping, you'll need to deal
with palm detection... So I have not actually enabled this in the end.
| Key |
Equivalent |
Effect |
Command |
| p |
Pause |
lock screen |
xset s activate |
| b |
Break |
? |
? |
| k |
ScrLk |
switch keyboard layout |
N/A |
It looks like those are
defined in the microcontroller so it
would be possible to add some. For example, the
SysRq key
is
almost bound to
fn s in there.
Note that most other shortcuts like this are clearly documented
(volume, brightness, etc). One key that's less obvious is
F12 that only has the Framework logo on it. That actually
calls the keysym
XF86AudioMedia which, interestingly, does
absolutely nothing here. By default, on Windows, it
opens your
browser to the Framework website and, on Linux, your "default
media player".
The keyboard backlight can be cycled with
fn-space. The
dimmer version is dim enough, and the keybinding is easy to find in
the dark.
A
skinny elephant would be performed with
alt
PrtScr (above
F11)
KEY, so for
example
alt fn F11 b
should do a hard reset.
This comment suggests you need to hold
the
fn only if "function lock" is
on, but that's
actually the opposite of my experience.
Out of the box, some of the
fn keys don't work. Mute,
volume up/down, brightness, monitor changes, and the airplane mode key
all do basically nothing. They don't send proper keysyms to Xorg at
all.
This is a
known problem and it's related to the fact that the
laptop has light sensors to adjust the brightness
automatically. Somehow some of those keys (e.g. the brightness
controls) are supposed to show up as a different input device, but
don't seem to work correctly. It seems like the solution is for the
Framework team to write a driver specifically for this, but
so far no
progress since July 2022.
In the meantime, the fancy functionality can be supposedly disabled with:
echo 'blacklist hid_sensor_hub' sudo tee /etc/modprobe.d/framework-als-blacklist.conf
... and a reboot. This solution is also
documented in the upstream
guide.
Note that there's another solution flying around that fixes this by
changing permissions on the input device but I haven't tested
that or seen confirmation it works.
Kill switches
The Framework has two "kill switches": one for the camera and the
other for the microphone. The camera one actually disconnects the USB
device when turned off, and the mic one seems to cut the circuit. It
doesn't show up as muted, it just stops feeding the sound.
Both kill switches are around the main camera, on top of the monitor,
and quite discreet. Then turn "red" when enabled (i.e. "red" means
"turned off").
Monitor
The monitor looks pretty good to my untrained eyes. I have yet to do
photography work on it, but some photos I looked at look sharp and the
colors are bright and lively. The blacks are dark and the screen is
bright.
I have yet to use it in full sunlight.
The dimmed light is very dim, which I like.
Screen backlight
I bind brightness keys to xbacklight in i3, but out of the box I get
this error:
sep 29 22:09:14 angela i3[5661]: No outputs have backlight property
It just requires this blob in /etc/X11/xorg.conf.d/backlight.conf:
Section "Device"
Identifier "Card0"
Driver "intel"
Option "Backlight" "intel_backlight"
EndSection
This way I can control the actual backlight power with the brightness
keys, and they do significantly reduce power usage.
Multiple monitor support
I have been able to hook up my two old monitors to the HDMI and
DisplayPort expansion cards on the laptop. The lid closes without
suspending the machine, and everything works great.
I actually run out of ports, even with a 4-port USB-A hub, which gives
me a total of 7 ports:
- power (USB-C)
- monitor 1 (DisplayPort)
- monitor 2 (HDMI)
- USB-A hub, which adds:
- keyboard (USB-A)
- mouse (USB-A)
- Yubikey
- external sound card
Now the latter, I might be able to get rid of if I switch to a
combo-jack headset, which I do have (and still need to test).
But still, this is a problem. I'll probably need a powered USB-C dock
and better monitors, possibly with some Thunderbolt chaining, to
save yet more ports.
But that means more money into this setup, argh. And figuring out my
monitor situation is the kind of thing I'm not that big
of a fan of. And neither is shopping for USB-C (or is it Thunderbolt?)
hubs.
My normal autorandr setup doesn't work: I have tried saving a
profile and it doesn't get autodetected, so I also first need to do:
autorandr -l framework-external-dual-lg-acer
The magic:
autorandr -l horizontal
... also works well.
The worst problem with those monitors right now is that they have a
radically smaller resolution than the main screen on the laptop, which
means I need to reset the font scaling to normal every time I switch
back and forth between those monitors and the laptop, which means I
actually need to do this:
autorandr -l horizontal &&
eho Xft.dpi: 96 xrdb -merge &&
systemctl restart terminal xcolortaillog background-image emacs &&
i3-msg restart
Kind of disruptive.
Expansion ports
I ordered a total of 10 expansion ports.
I did manage to initialize the 1TB drive as an encrypted storage,
mostly to keep photos as this is something that takes a massive amount
of space (500GB and counting) and that I (unfortunately) don't work on
very often (but still carry around).
The expansion ports are fancy and nice, but not actually that
convenient. They're a bit hard to take out: you really need to crimp
your fingernails on there and pull hard to take them out. There's a
little button next to them to release, I think, but at first it feels
a little scary to pull those pucks out of there. You get used to it
though, and it's one of those things you can do without looking
eventually.
There's only four expansion ports. Once you have two monitors, the
drive, and power plugged in, bam, you're out of ports; there's nowhere
to plug my Yubikey. So if this is going to be my daily driver, with a
dual monitor setup, I will need a dock, which means more crap firmware
and uncertainty, which isn't great. There are actually plans to make a
dual-USB card, but that is blocked on designing an actual
board for this.
I can't wait to see more expansion ports produced. There's a ethernet
expansion card which quickly went out of stock basically the day
it was announced, but was eventually restocked.
I would like to see a proper SD-card reader. There's a MicroSD card
reader, but that obviously doesn't work for normal SD cards, which
would be more broadly compatible anyways (because you can have a
MicroSD to SD card adapter, but I have never heard of the
reverse). Someone actually found a SD card reader that fits and
then someone else managed to cram it in a 3D printed case, which
is kind of amazing.
Still, I really like that idea that I can carry all those little
adapters in a pouch when I travel and can basically do anything I
want. It does mean I need to shuffle through them to find the right
one which is a little annoying. I have an elastic band to keep them
lined up so that all the ports show the same side, to make it easier
to find the right one. But that quickly gets undone and instead I have
a pouch full of expansion cards.
Another awesome thing with the expansion cards is that they don't just
work on the laptop: anything that takes USB-C can take those cards,
which means you can use it to connect an SD card to your phone, for
backups, for example. Heck, you could even connect an external display
to your phone that way, assuming that's supported by your phone of
course (and it probably isn't).
The expansion ports do take up some power, even when idle. See the
power management section below, and particularly the power usage
tests for details.
USB-C charging
One thing that is really a game changer for me is USB-C charging. It's
hard to overstate how convenient this is. I often have a USB-C cable
lying around to charge my phone, and I can just grab that thing and
pop it in my laptop. And while it will obviously not charge as fast as
the provided charger, it will stop draining the battery at least.
(As I wrote this, I had the laptop plugged in the Samsung charger that
came with a phone, and it was telling me it would take 6 hours to
charge the remaining 15%. With the provided charger, that flew down to
15 minutes. Similarly, I can power the laptop from the power grommet
on my desk, reducing clutter as I have that single wire out there
instead of the bulky power adapter.)
I also really like the idea that I can charge my laptop with a power
bank or, heck, with my phone, if push comes to shove. (And
vice-versa!)
This is awesome. And it works from any of the expansion ports, of
course. There's a little led next to the expansion ports as well,
which indicate the charge status:
- red/amber: charging
- white: charged
- off: unplugged
I couldn't find documentation about this, but the forum
answered.
This is something of a recurring theme with the Framework. While it
has a good knowledge base and repair/setup guides (and the
forum is awesome) but it doesn't have a good "owner manual" that
shows you the different parts of the laptop and what they do. Again,
something the MNT reform did well.
Another thing that people are asking about is an external sleep
indicator: because the power LED is on the main keyboard assembly,
you don't actually see whether the device is active or not when the
lid is closed.
Finally, I wondered what happens when you plug in multiple power
sources and it turns out the charge controller is actually pretty
smart: it will pick the best power source and use it. The only
downside is it can't use multiple power sources, but that seems like
a bit much to ask.
Multimedia and other devices
Those things also work:
- webcam: splendid, best webcam I've ever had (but my standards are
really low)
- onboard mic: works well, good gain (maybe a bit much)
- onboard speakers: sound okay, a little metal-ish, loud enough to be
annoying, see this thread for benchmarks, apparently pretty
good speakers
- combo jack: works, with slight hiss, see below
There's also a light sensor, but it conflicts with the keyboard
brightness controls (see above).
There's also an accelerometer, but it's off by default and
will be removed from future builds.
Combo jack mic tests
The Framework laptop ships with a combo jack on the left side, which
allows you to plug in a CTIA (source) headset. In human
terms, it's a device that has both a stereo output and a mono input,
typically a headset or ear buds with a microphone somewhere.
It works, which is better than the Purism (which only had audio
out), but is on par for the course for that kind of onboard
hardware. Because of electrical interference, such sound cards very
often get lots of noise from the board.
With a Jabra Evolve 40, the built-in USB sound card generates
basically zero noise on silence (invisible down to -60dB in Audacity)
while plugging it in directly generates a solid -30dB hiss. There is
a noise-reduction system in that sound card, but the difference is
still quite striking.
On a comparable setup (curie, a 2017 Intel NUC), there is
also a his with the Jabra headset, but it's quieter, more in the order
of -40/-50 dB, a noticeable difference. Interestingly, testing with my
Mee Audio Pro M6 earbuds leads to a little more hiss on curie, more on
the -35/-40 dB range, close to the Framework.
Also note that another sound card, the Antlion USB adapter that comes
with the ModMic 4, also gives me pretty close to silence on a quiet
recording, picking up less than -50dB of background noise. It's
actually probably picking up the fans in the office, which do make
audible noises.
In other words, the hiss of the sound card built in the Framework
laptop is so loud that it makes more noise than the quiet fans in the
office. Or, another way to put it is that two USB sound cards (the
Jabra and the Antlion) are able to pick up ambient noise in my office
but not the Framework laptop.
See also my audio page.
Performance tests
Compiling Linux 5.19.11
On a single core, compiling the Debian version of the Linux kernel
takes around 100 minutes:
5411.85user 673.33system 1:37:46elapsed 103%CPU (0avgtext+0avgdata 831700maxresident)k
10594704inputs+87448000outputs (9131major+410636783minor)pagefaults 0swaps
This was using 16 watts of power, with full screen brightness.
With all 16 cores (make -j16), it takes less than 25 minutes:
19251.06user 2467.47system 24:13.07elapsed 1494%CPU (0avgtext+0avgdata 831676maxresident)k
8321856inputs+87427848outputs (30792major+409145263minor)pagefaults 0swaps
I had to plug the normal power supply after a few minutes because
battery would actually run out using my desk's power grommet (34
watts).
During compilation, fans were spinning really hard, quite noisy, but
not painfully so.
The laptop was sucking 55 watts of power, steadily:
Time User Nice Sys Idle IO Run Ctxt/s IRQ/s Fork Exec Exit Watts
-------- ----- ----- ----- ----- ----- ---- ------ ------ ---- ---- ---- ------
Average 87.9 0.0 10.7 1.4 0.1 17.8 6583.6 5054.3 233.0 223.9 233.1 55.96
GeoMean 87.9 0.0 10.6 1.2 0.0 17.6 6427.8 5048.1 227.6 218.7 227.7 55.96
StdDev 1.4 0.0 1.2 0.6 0.2 3.0 1436.8 255.5 50.0 47.5 49.7 0.20
-------- ----- ----- ----- ----- ----- ---- ------ ------ ---- ---- ---- ------
Minimum 85.0 0.0 7.8 0.5 0.0 13.0 3594.0 4638.0 117.0 111.0 120.0 55.52
Maximum 90.8 0.0 12.9 3.5 0.8 38.0 10174.0 5901.0 374.0 362.0 375.0 56.41
-------- ----- ----- ----- ----- ----- ---- ------ ------ ---- ---- ---- ------
Summary:
CPU: 55.96 Watts on average with standard deviation 0.20
Note: power read from RAPL domains: package-0, uncore, package-0, core, psys.
These readings do not cover all the hardware in this device.
memtest86+
I ran Memtest86+ v6.00b3. It shows something like this:
Memtest86+ v6.00b3 12th Gen Intel(R) Core(TM) i5-1240P
CLK/Temp: 2112MHz 78/78 C Pass 2% #
L1 Cache: 48KB 414 GB/s Test 46% ##################
L2 Cache: 1.25MB 118 GB/s Test #3 [Moving inversions, 1s & 0s]
L3 Cache: 12MB 43 GB/s Testing: 16GB - 18GB [1GB of 15.7GB]
Memory : 15.7GB 14.9 GB/s Pattern:
--------------------------------------------------------------------------------
CPU: 4P+8E-Cores (16T) SMP: 8T (PAR)) Time: 0:27:23 Status: Pass \
RAM: 1600MHz (DDR4-3200) CAS 22-22-22-51 Pass: 1 Errors: 0
--------------------------------------------------------------------------------
Memory SPD Information
----------------------
- Slot 2: 16GB DDR-4-3200 - Crucial CT16G4SFRA32A.C16FP (2022-W23)
Framework FRANMACP04
<ESC> Exit <F1> Configuration <Space> Scroll Lock 6.00.unknown.x64
So about 30 minutes for a full 16GB memory test.
Software setup
Once I had everything in the hardware setup, I figured, voil , I'm
done, I'm just going to boot this beautiful machine and I can get back
to work.
I don't understand why I am so na ve some times. It's mind boggling.
Obviously, it didn't happen that way at all, and I spent the best of
the three following days tinkering with the laptop.
Secure boot and EFI
First, I couldn't boot off of the NVMe drive I transferred from the
previous laptop (the Purism) and the
BIOS was not very helpful: it was just complaining about not finding
any boot device, without dropping me in the real BIOS.
At first, I thought it was a problem with my NVMe drive, because it's
not listed in the compatible SSD drives from upstream. But I
figured out how to enter BIOS (press F2 manically, of
course), which showed the NVMe drive was actually detected. It just
didn't boot, because it was an old (2010!!) Debian install without
EFI.
So from there, I disabled secure boot, and booted a grml image to
try to recover. And by "boot" I mean, I managed to get to the grml
boot loader which promptly failed to load its own root file system
somehow. I still have to investigate exactly what happened there, but
it failed some time after the initrd load with:
Unable to find medium containing a live file system
This, it turns out, was fixed in Debian lately, so a daily GRML
build will not have this problems. The upcoming 2022 release
(likely 2022.10 or 2022.11) will also get the fix.
I did manage to boot the development version of the Debian
installer which was a surprisingly good experience: it mounted the
encrypted drives and did everything pretty smoothly. It even offered
me to reinstall the boot loader, but that ultimately (and correctly, as
it turns out) failed because I didn't have a /boot/efi partition.
At this point, I realized there was no easy way out of this, and I
just proceeded to completely reinstall Debian. I had a spare NVMe
drive lying around (backups FTW!) so I just swapped that in, rebooted
in the Debian installer, and did a clean install. I wanted to switch
to bookworm anyways, so I guess that's done too.
Storage limitations
Another thing that happened during setup is that I tried to copy over
the internal 2.5" SSD drive from the Purism to the Framework 1TB
expansion card. There's no 2.5" slot in the new laptop, so that's
pretty much the only option for storage expansion.
I was tired and did something wrong. I ended up wiping the partition
table on the original 2.5" drive.
Oops.
It might be recoverable, but just restoring the partition table
didn't work either, so I'm not sure how I recover the data
there. Normally, everything on my laptops and workstations is designed
to be disposable, so that wasn't that big of a problem. I did manage
to recover most of the data thanks to git-annex reinit, but
that was a little hairy.
Bootstrapping Puppet
Once I had some networking, I had to install all the packages I
needed. The time I spent setting up my workstations with Puppet has
finally paid off. What I actually did was to restore two critical
directories:
/etc/ssh
/var/lib/puppet
So that I would keep the previous machine's identity. That way I could
contact the Puppet server and install whatever was missing. I used my
Puppet optimization
trick to do a batch
install and then I had a good base setup, although not exactly as it
was before. 1700 packages were installed manually on angela before
the reinstall, and not in Puppet.
I did not inspect each one individually, but I did go through /etc
and copied over more SSH keys, for backups and SMTP over SSH.
LVFS support
It looks like there's support for the (de-facto) standard LVFS
firmware update system. At least I was able to update the UEFI
firmware with a simple:
apt install fwupd-amd64-signed
fwupdmgr refresh
fwupdmgr get-updates
fwupdmgr update
Nice. The 12th gen BIOS updates, currently (January 2023) beta,
can be deployed through LVFS with:
fwupdmgr enable-remote lvfs-testing
echo 'DisableCapsuleUpdateOnDisk=true' >> /etc/fwupd/uefi_capsule.conf
fwupdmgr update
Those instructions come from the beta forum post. I performed the
BIOS update on 2023-01-16T16:00-0500.
Resolution tweaks
The Framework laptop resolution (2256px X 1504px) is big enough to
give you a pretty small font size, so welcome to the marvelous world
of "scaling".
The Debian wiki page has a few tricks for this.
Console
This will make the console and grub fonts more readable:
cat >> /etc/default/console-setup <<EOF
FONTFACE="Terminus"
FONTSIZE=32x16
EOF
echo GRUB_GFXMODE=1024x768 >> /etc/default/grub
update-grub
Xorg
Adding this to your .Xresources will make everything look much bigger:
! 1.5*96
Xft.dpi: 144
Apparently, some of this can also help:
! These might also be useful depending on your monitor and personal preference:
Xft.autohint: 0
Xft.lcdfilter: lcddefault
Xft.hintstyle: hintfull
Xft.hinting: 1
Xft.antialias: 1
Xft.rgba: rgb
It my experience it also makes things look a little fuzzier, which is
frustrating because you have this awesome monitor but everything looks
out of focus. Just bumping Xft.dpi by a 1.5 factor looks good to me.
The Debian Wiki has a page on HiDPI, but it's not as good as the
Arch Wiki, where the above blurb comes from. I am not using the
latter because I suspect it's causing some of the "fuzziness".
TODO: find the equivalent of this GNOME hack in i3? (gsettings set
org.gnome.mutter experimental-features
"['scale-monitor-framebuffer']"), taken from this Framework
guide
Issues
BIOS configuration
The Framework BIOS has some minor issues. One issue I personally
encountered is that I had disabled Quick boot and Quiet boot in
the BIOS to diagnose the above boot issues. This, in turn, triggers a
bug where the BIOS boot manager (F12) would just hang
completely. It would also fail to boot from an external USB drive.
The current fix (as of BIOS 3.03) is to re-enable both Quick
boot and Quiet boot. Presumably this is something that will get
fixed in a future BIOS update.
Note that the following keybindings are active in the BIOS POST
check:
| Key |
Meaning |
| F2 |
Enter BIOS setup menu |
| F12 |
Enter BIOS boot manager |
| Delete |
Enter BIOS setup menu |
WiFi compatibility issues
I couldn't make WiFi work at first. Obviously, the default Debian
installer doesn't ship with proprietary firmware (although that might
change soon) so the WiFi card didn't work out of the box. But even
after copying the firmware through a USB stick, I couldn't quite
manage to find the right combination of ip/iw/wpa-supplicant
(yes, after repeatedly copying a bunch more packages over to get
those bootstrapped). (Next time I should probably try something like
this post.)
Thankfully, I had a little USB-C dongle with a RJ-45 jack lying
around. That also required a firmware blob, but it was a single
package to copy over, and with that loaded, I had network.
Eventually, I did managed to make WiFi work; the problem was more on
the side of "I forgot how to configure a WPA network by hand from the
commandline" than anything else. NetworkManager worked fine and got
WiFi working correctly.
Note that this is with Debian bookworm, which has the 5.19 Linux
kernel, and with the firmware-nonfree (firmware-iwlwifi,
specifically) package.
Battery life
I was having between about 7 hours of battery on the Purism Librem
13v4, and that's after a year or two of battery life. Now, I still
have about 7 hours of battery life, which is nicer than my old
ThinkPad X220 (20 minutes!) but really, it's not that good for a new
generation laptop. The 12th generation Intel chipset probably improved
things compared to the previous one Framework laptop, but I don't have
a 11th gen Framework to compare with).
(Note that those are estimates from my status bar, not wall clock
measurements. They should still be comparable between the Purism and
Framework, that said.)
The battery life doesn't seem up to, say, Dell XPS 13, ThinkPad X1, and
of course not the Apple M1, where I would expect 10+ hours of battery
life out of the box.
That said, I do get those kind estimates when the machine is fully
charged and idle. In fact, when everything is quiet and nothing is
plugged in, I get dozens of hours of battery life estimated (I've
seen 25h!). So power usage fluctuates quite a bit depending on usage,
which I guess is expected.
Concretely, so far, light web browsing, reading emails and writing
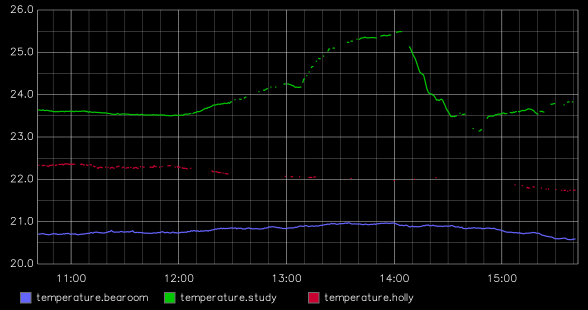
notes in Emacs (e.g. this file) takes about 8W of power:
Time User Nice Sys Idle IO Run Ctxt/s IRQ/s Fork Exec Exit Watts
-------- ----- ----- ----- ----- ----- ---- ------ ------ ---- ---- ---- ------
Average 1.7 0.0 0.5 97.6 0.2 1.2 4684.9 1985.2 126.6 39.1 128.0 7.57
GeoMean 1.4 0.0 0.4 97.6 0.1 1.2 4416.6 1734.5 111.6 27.9 113.3 7.54
StdDev 1.0 0.2 0.2 1.2 0.0 0.5 1584.7 1058.3 82.1 44.0 80.2 0.71
-------- ----- ----- ----- ----- ----- ---- ------ ------ ---- ---- ---- ------
Minimum 0.2 0.0 0.2 94.9 0.1 1.0 2242.0 698.2 82.0 17.0 82.0 6.36
Maximum 4.1 1.1 1.0 99.4 0.2 3.0 8687.4 4445.1 463.0 249.0 449.0 9.10
-------- ----- ----- ----- ----- ----- ---- ------ ------ ---- ---- ---- ------
Summary:
System: 7.57 Watts on average with standard deviation 0.71
Expansion cards matter a lot in the battery life (see below for a
thorough discussion), my normal setup is 2xUSB-C and 1xUSB-A (yes,
with an empty slot, and yes, to save power).
Interestingly, playing a video in a (720p) window in a window takes up
more power (10.5W) than in full screen (9.5W) but I blame that on my
desktop setup (i3 + compton)... Not sure if mpv hits the
VA-API, maybe not in windowed mode. Similar results with 1080p,
interestingly, except the window struggles to keep up altogether. Full
screen playback takes a relatively comfortable 9.5W, which means a
solid 5h+ of playback, which is fine by me.
Fooling around the web, small edits, youtube-dl, and I'm at around 80%
battery after about an hour, with an estimated 5h left, which is a
little disappointing. I had a 7h remaining estimate before I started
goofing around Discourse, so I suspect the website is a pretty
big battery drain, actually. I see about 10-12 W, while I was probably at
half that (6-8W) just playing music with mpv in the background...
In other words, it looks like editing posts in Discourse with Firefox
takes a solid 4-6W of power. Amazing and gross.
(When writing about abusive power usage generates more power usage, is
that an heisenbug? Or schr dinbug?)
Power management
Compared to the Purism Librem 13v4, the ongoing power usage seems to
be slightly better. An anecdotal metric is that the Purism would take
800mA idle, while the more powerful Framework manages a little over
500mA as I'm typing this, fluctuating between 450 and 600mA. That is
without any active expansion card, except the storage. Those numbers
come from the output of tlp-stat -b and, unfortunately, the "ampere"
unit makes it quite hard to compare those, because voltage is not
necessarily the same between the two platforms.
- TODO: review Arch Linux's tips on power saving
- TODO: i915 driver has a lot of parameters, including some about
power saving, see, again, the arch wiki, and particularly
enable_fbc=1
TL:DR; power management on the laptop is an issue, but there's various
tweaks you can make to improve it. Try:
powertop --auto-tuneapt install tlp && systemctl enable tlpnvme.noacpi=1 mem_sleep_default=deep on the kernel command line
may help with standby power usage- keep only USB-C expansion cards plugged in, all others suck power
even when idle
- consider upgrading the BIOS to latest beta (3.06 at the time of
writing), unverified power savings
- latest Linux kernels (6.2) promise power savings as well
(unverified)
Update: also try to follow the official optimization guide. It
was made for Ubuntu but will probably also work for your distribution
of choice with a few tweaks. They recommend using tlpui but it's
not packaged in Debian. There is, however, a Flatpak
release. In my case, it resulted in the following diff to
tlp.conf: tlp.patch.
Background on CPU architecture
There were power problems in the 11th gen Framework laptop, according
to this report from Linux After Dark, so the issues with power
management on the Framework are not new.
The 12th generation Intel CPU (AKA "Alder Lake") is a big-little
architecture with "power-saving" and "performance" cores. There
used to be performance problems introduced by the scheduler in Linux
5.16 but those were eventually fixed in 5.18, which uses
Intel's hardware as an "intelligent, low-latency hardware-assisted
scheduler". According to Phoronix, the 5.19 release improved the
power saving, at the cost of some penalty cost. There were also patch
series to make the scheduler configurable, but it doesn't look
those have been merged as of 5.19. There was also a session about this
at the 2022 Linux Plumbers, but they stopped short of
talking more about the specific problems Linux is facing in Alder
lake:
Specifically, the kernel's energy-aware scheduling heuristics don't
work well on those CPUs. A number of features present there
complicate the energy picture; these include SMT, Intel's "turbo
boost" mode, and the CPU's internal power-management mechanisms. For
many workloads, running on an ostensibly more power-hungry Pcore can
be more efficient than using an Ecore. Time for discussion of the
problem was lacking, though, and the session came to a close.
All this to say that the 12gen Intel line shipped with this Framework
series should have better power management thanks to its
power-saving cores. And Linux has had the scheduler changes to make
use of this (but maybe is still having trouble). In any case, this
might not be the source of power management problems on my laptop,
quite the opposite.
Also note that the firmware updates for various chipsets are
supposed to improve things eventually.
On the other hand, The Verge simply declared the whole P-series
a mistake...
Attempts at improving power usage
I did try to follow some of the tips in this forum post. The
tricks powertop --auto-tune and tlp's
PCIE_ASPM_ON_BAT=powersupersave basically did nothing: I was stuck
at 10W power usage in powertop (600+mA in tlp-stat).
Apparently, I should be able to reach the C8 CPU power state (or
even C9, C10) in powertop, but I seem to be stock at
C7. (Although I'm not sure how to read that tab in powertop: in the
Core(HW) column there's only C3/C6/C7 states, and most cores are 85%
in C7 or maybe C6. But the next column over does show many CPUs in
C10 states...
As it turns out, the graphics card actually takes up a good chunk of
power unless proper power management is enabled (see below). After
tweaking this, I did manage to get down to around 7W power usage in
powertop.
Expansion cards actually do take up power, and so does the screen,
obviously. The fully-lit screen takes a solid 2-3W of power compared
to the fully dimmed screen. When removing all expansion cards and
making the laptop idle, I can spin it down to 4 watts power usage at
the moment, and an amazing 2 watts when the screen turned off.
Caveats
Abusive (10W+) power usage that I initially found could be a problem
with my desktop configuration: I have this silly status bar that
updates every second and probably causes redraws... The CPU certainly
doesn't seem to spin down below 1GHz. Also note that this is with an
actual desktop running with everything: it could very well be that
some things (I'm looking at you Signal Desktop) take up unreasonable
amount of power on their own (hello, 1W/electron, sheesh). Syncthing
and containerd (Docker!) also seem to take a good 500mW just sitting
there.
Beyond my desktop configuration, this could, of course, be a
Debian-specific problem; your favorite distribution might be better at
power management.
Idle power usage tests
Some expansion cards waste energy, even when unused. Here is a summary
of the findings from the powerstat page. I also include other
devices tested in this page for completeness:
| Device |
Minimum |
Average |
Max |
Stdev |
Note |
| Screen, 100% |
2.4W |
2.6W |
2.8W |
N/A |
|
| Screen, 1% |
30mW |
140mW |
250mW |
N/A |
|
| Backlight 1 |
290mW |
? |
? |
? |
fairly small, all things considered |
| Backlight 2 |
890mW |
1.2W |
3W? |
460mW? |
geometric progression |
| Backlight 3 |
1.69W |
1.5W |
1.8W? |
390mW? |
significant power use |
| Radios |
100mW |
250mW |
N/A |
N/A |
|
| USB-C |
N/A |
N/A |
N/A |
N/A |
negligible power drain |
| USB-A |
10mW |
10mW |
? |
10mW |
almost negligible |
| DisplayPort |
300mW |
390mW |
600mW |
N/A |
not passive |
| HDMI |
380mW |
440mW |
1W? |
20mW |
not passive |
| 1TB SSD |
1.65W |
1.79W |
2W |
12mW |
significant, probably higher when busy |
| MicroSD |
1.6W |
3W |
6W |
1.93W |
highest power usage, possibly even higher when busy |
| Ethernet |
1.69W |
1.64W |
1.76W |
N/A |
comparable to the SSD card |
So it looks like
all expansion cards but the USB-C ones are active,
i.e. they draw power with idle. The USB-A cards are the least concern,
sucking out 10mW, pretty much within the margin of error. But both the
DisplayPort and HDMI do take a few hundred miliwatts. It looks like
USB-A connectors have this fundamental flaw that they necessarily draw
some powers because they lack the power negotiation features of
USB-C. At least
according to this post:
It seems the USB A must have power going to it all the time, that
the old USB 2 and 3 protocols, the USB C only provides power when
there is a connection. Old versus new.
Apparently, this is a problem
specific to the USB-C to USB-A
adapter that ships with the Framework. Some people have
actually
changed their orders to all USB-C because of this problem, but I'm
not sure the problem is as serious as claimed in the forums. I
couldn't reproduce the "one watt" power drains suggested elsewhere,
at least not repeatedly. (A previous version of this post
did show
such a power drain, but it was in a less controlled test
environment than the series of more rigorous tests above.)
The worst offenders are the storage cards: the SSD drive takes at
least one watt of power and the MicroSD card seems to want to take all
the way up to 6 watts of power, both just sitting there doing
nothing. This confirms claims of
1.4W for the SSD (but not
5W) power usage found elsewhere. The
former post has
instructions on how to disable the card in software. The MicroSD card
has been reported as
using 2 watts, but I've seen it as high as 6
watts, which is pretty damning.
The Framework team has
a beta update for the DisplayPort adapter
but currently only for Windows (
LVFS technically possible, "under
investigation"). A USB-A firmware update is
also under
investigation. It is therefore likely at least some of those power
management issues will eventually be fixed.
Note that the upcoming
Ethernet card has a reported 2-8W power usage,
depending on traffic. I did my own power usage tests in
powerstat-wayland and they seem lower than 2W.
The upcoming 6.2 Linux kernel might also improve battery usage when
idle, see
this Phoronix article for details, likely in early
2023.
Idle power usage tests under Wayland
Update: I redid those tests under Wayland, see powerstat-wayland
for details. The TL;DR: is that power consumption is either smaller or
similar.
Idle power usage tests, 3.06 beta BIOS
I redid the idle tests after the 3.06 beta BIOS update and ended
up with this results:
| Device |
Minimum |
Average |
Max |
Stdev |
Note |
| Baseline |
1.96W |
2.01W |
2.11W |
30mW |
1 USB-C, screen off, backlight off, no radios |
| 2 USB-C |
1.95W |
2.16W |
3.69W |
430mW |
USB-C confirmed as mostly passive... |
| 3 USB-C |
1.95W |
2.16W |
3.69W |
430mW |
... although with extra stdev |
| 1TB SSD |
3.72W |
3.85W |
4.62W |
200mW |
unchanged from before upgrade |
| 1 USB-A |
1.97W |
2.18W |
4.02W |
530mW |
unchanged |
| 2 USB-A |
1.97W |
2.00W |
2.08W |
30mW |
unchanged |
| 3 USB-A |
1.94W |
1.99W |
2.03W |
20mW |
unchanged |
| MicroSD w/o card |
3.54W |
3.58W |
3.71W |
40mW |
significant improvement! 2-3W power saving! |
| MicroSD w/ card |
3.53W |
3.72W |
5.23W |
370mW |
new measurement! increased deviation |
| DisplayPort |
2.28W |
2.31W |
2.37W |
20mW |
unchanged |
| 1 HDMI |
2.43W |
2.69W |
4.53W |
460mW |
unchanged |
| 2 HDMI |
2.53W |
2.59W |
2.67W |
30mW |
unchanged |
| External USB |
3.85W |
3.89W |
3.94W |
30mW |
new result |
| Ethernet |
3.60W |
3.70W |
4.91W |
230mW |
unchanged |
Note that the table summary is different than the previous table: here
we show the absolute numbers while the previous table was doing a
confusing attempt at showing relative (to the baseline) numbers.
Conclusion: the 3.06 BIOS update did not significantly change idle
power usage stats
except for the MicroSD card which has
significantly improved.
The new "external USB" test is also interesting: it shows how the
provided 1TB SSD card performs (admirably) compared to existing
devices. The other new result is the MicroSD card with a card which,
interestingly, uses
less power than the 1TB SSD drive.
Standby battery usage
I wrote some quick hack to evaluate how much power is used during
sleep. Apparently, this is one
of the areas that should have improved since the first Framework
model, let's find out.
My baseline for comparison is the Purism laptop, which, in 10 minutes,
went from this:
sep 28 11:19:45 angela systemd-sleep[209379]: /sys/class/power_supply/BAT/charge_now = 6045 [mAh]
... to this:
sep 28 11:29:47 angela systemd-sleep[209725]: /sys/class/power_supply/BAT/charge_now = 6037 [mAh]
That's 8mAh per 10 minutes (and 2 seconds), or 48mA, or, with this
battery, about 127 hours or roughly 5 days of standby. Not bad!
In comparison, here is my really old x220, before:
sep 29 22:13:54 emma systemd-sleep[176315]: /sys/class/power_supply/BAT0/energy_now = 5070 [mWh]
... after:
sep 29 22:23:54 emma systemd-sleep[176486]: /sys/class/power_supply/BAT0/energy_now = 4980 [mWh]
... which is 90 mwH in 10 minutes, or a whopping 540mA, which was
possibly okay when this battery was new (62000 mAh, so about 100
hours, or about 5 days), but this battery is almost dead and has
only 5210 mAh when full, so only 10 hours standby.
And here is the Framework performing a similar test, before:
sep 29 22:27:04 angela systemd-sleep[4515]: /sys/class/power_supply/BAT1/charge_full = 3518 [mAh]
sep 29 22:27:04 angela systemd-sleep[4515]: /sys/class/power_supply/BAT1/charge_now = 2861 [mAh]
... after:
sep 29 22:37:08 angela systemd-sleep[4743]: /sys/class/power_supply/BAT1/charge_now = 2812 [mAh]
... which is 49mAh in a little over 10 minutes (and 4 seconds), or
292mA, much more than the Purism, but half of the X220. At this rate,
the battery would last on standby only 12 hours!! That is pretty
bad.
Note that this was done with the following expansion cards:
- 2 USB-C
- 1 1TB SSD drive
- 1 USB-A with a hub connected to it, with keyboard and LAN
Preliminary tests without the hub (over one minute) show that it
doesn't significantly affect this power consumption (300mA).
This guide also suggests booting with nvme.noacpi=1 but this
still gives me about 5mAh/min (or 300mA).
Adding mem_sleep_default=deep to the kernel command line does make a
difference. Before:
sep 29 23:03:11 angela systemd-sleep[3699]: /sys/class/power_supply/BAT1/charge_now = 2544 [mAh]
... after:
sep 29 23:04:25 angela systemd-sleep[4039]: /sys/class/power_supply/BAT1/charge_now = 2542 [mAh]
... which is 2mAh in 74 seconds, which is 97mA, brings us to a more
reasonable 36 hours, or a day and a half. It's still above the x220
power usage, and more than an order of magnitude more than the Purism
laptop. It's also far from the 0.4% promised by upstream, which
would be 14mA for the 3500mAh battery.
It should also be noted that this "deep" sleep mode is a little more
disruptive than regular sleep. As you can see by the timing, it took
more than 10 seconds for the laptop to resume, which feels a little
alarming as your banging the keyboard to bring it back to life.
You can confirm the current sleep mode with:
# cat /sys/power/mem_sleep
s2idle [deep]
In the above, deep is selected. You can change it on the fly with:
printf s2idle > /sys/power/mem_sleep
Here's another test:
sep 30 22:25:50 angela systemd-sleep[32207]: /sys/class/power_supply/BAT1/charge_now = 1619 [mAh]
sep 30 22:31:30 angela systemd-sleep[32516]: /sys/class/power_supply/BAT1/charge_now = 1613 [mAh]
... better! 6 mAh in about 6 minutes, works out to 63.5mA, so more
than two days standby.
A longer test:
oct 01 09:22:56 angela systemd-sleep[62978]: /sys/class/power_supply/BAT1/charge_now = 3327 [mAh]
oct 01 12:47:35 angela systemd-sleep[63219]: /sys/class/power_supply/BAT1/charge_now = 3147 [mAh]
That's 180mAh in about 3.5h, 52mA! Now at 66h, or almost 3 days.
I wasn't sure why I was seeing such fluctuations in those tests, but
as it turns out, expansion card power tests show that they do
significantly affect power usage, especially the SSD drive, which can
take up to two full watts of power even when idle. I didn't control
for expansion cards in the above tests running them with whatever
card I had plugged in without paying attention so it's likely the
cause of the high power usage and fluctuations.
It might be possible to work around this problem by disabling USB
devices before suspend. TODO. See also this post.
In the meantime, I have been able to get much better suspend
performance by unplugging all modules. Then I get this result:
oct 04 11:15:38 angela systemd-sleep[257571]: /sys/class/power_supply/BAT1/charge_now = 3203 [mAh]
oct 04 15:09:32 angela systemd-sleep[257866]: /sys/class/power_supply/BAT1/charge_now = 3145 [mAh]
Which is 14.8mA! Almost exactly the number promised by Framework! With
a full battery, that means a 10 days suspend time. This is actually
pretty good, and far beyond what I was expecting when starting down
this journey.
So, once the expansion cards are unplugged, suspend power usage is
actually quite reasonable. More detailed standby tests are available
in the standby-tests page, with a summary below.
There is also some hope that the Chromebook edition
specifically designed with a specification of 14 days standby
time could bring some firmware improvements back down to the
normal line. Some of those issues were reported upstream in April
2022, but there doesn't seem to have been any progress there
since.
TODO: one final solution here is suspend-then-hibernate, which
Windows uses for this
TODO: consider implementing the S0ix sleep states , see also troubleshooting
TODO: consider https://github.com/intel/pm-graph
Standby expansion cards test results
This table is a summary of the more extensive standby-tests I have performed:
| Device |
Wattage |
Amperage |
Days |
Note |
| baseline |
0.25W |
16mA |
9 |
sleep=deep nvme.noacpi=1 |
| s2idle |
0.29W |
18.9mA |
~7 |
sleep=s2idle nvme.noacpi=1 |
| normal nvme |
0.31W |
20mA |
~7 |
sleep=s2idle without nvme.noacpi=1 |
| 1 USB-C |
0.23W |
15mA |
~10 |
|
| 2 USB-C |
0.23W |
14.9mA |
|
same as above |
| 1 USB-A |
0.75W |
48.7mA |
3 |
+500mW (!!) for the first USB-A card! |
| 2 USB-A |
1.11W |
72mA |
2 |
+360mW |
| 3 USB-A |
1.48W |
96mA |
<2 |
+370mW |
| 1TB SSD |
0.49W |
32mA |
<5 |
+260mW |
| MicroSD |
0.52W |
34mA |
~4 |
+290mW |
| DisplayPort |
0.85W |
55mA |
<3 |
+620mW (!!) |
| 1 HDMI |
0.58W |
38mA |
~4 |
+250mW |
| 2 HDMI |
0.65W |
42mA |
<4 |
+70mW |
Conclusions:
- USB-C cards take no extra power on suspend, possibly less
than empty slots, more testing required
- USB-A cards take a lot more power on suspend
(300-500mW) than on regular idle (~10mW, almost negligible)
- 1TB SSD and MicroSD cards seem to take a reasonable
amount of power (260-290mW), compared to their runtime
equivalents (1-6W!)
- DisplayPort takes a surprising lot of power (620mW), almost
double its average runtime usage (390mW)
- HDMI cards take, surprisingly, less power (250mW) in
standby than the DP card (620mW)
- and oddly, a second card adds less power usage (70mW?!) than the
first, maybe a circuit is used by both?
A discussion of those results is in
this forum post.
Standby expansion cards test results, 3.06 beta BIOS
Framework recently (2022-11-07) announced that they will publish
a firmware upgrade to address some of the USB-C issues, including
power management. This could positively affect the above result,
improving both standby and runtime power usage.
The update came out in December 2022 and I redid my analysis with
the following results:
| Device |
Wattage |
Amperage |
Days |
Note |
| baseline |
0.25W |
16mA |
9 |
no cards, same as before upgrade |
| 1 USB-C |
0.25W |
16mA |
9 |
same as before |
| 2 USB-C |
0.25W |
16mA |
9 |
same |
| 1 USB-A |
0.80W |
62mA |
3 |
+550mW!! worse than before |
| 2 USB-A |
1.12W |
73mA |
<2 |
+320mW, on top of the above, bad! |
| Ethernet |
0.62W |
40mA |
3-4 |
new result, decent |
| 1TB SSD |
0.52W |
34mA |
4 |
a bit worse than before (+2mA) |
| MicroSD |
0.51W |
22mA |
4 |
same |
| DisplayPort |
0.52W |
34mA |
4+ |
upgrade improved by 300mW |
| 1 HDMI |
? |
38mA |
? |
same |
| 2 HDMI |
? |
45mA |
? |
a bit worse than before (+3mA) |
| Normal |
1.08W |
70mA |
~2 |
Ethernet, 2 USB-C, USB-A |
Full results in
standby-tests-306. The big takeaway for me is that
the update did
not improve power usage on the USB-A ports which is a
big problem for my use case. There is a notable improvement on the
DisplayPort power consumption which brings it more in line with the
HDMI connector, but it still doesn't properly turn off on suspend
either.
Even worse, the USB-A ports now sometimes
fails to resume after
suspend, which is pretty annoying. This is a
known problem
that will hopefully get fixed in the final release.
Battery wear protection
The BIOS has an option to limit charge to 80% to mitigate battery
wear. There's a way to control the embedded controller from
runtime with fw-ectool, partly documented here. The command
would be:
sudo ectool fwchargelimit 80
I looked at building this myself but failed to run it. I opened a
RFP in Debian so that we can ship this in Debian, and also documented
my work there.
Note that there is now a counter that tracks charge/discharge
cycles. It's visible in tlp-stat -b, which is a nice
improvement:
root@angela:/home/anarcat# tlp-stat -b
--- TLP 1.5.0 --------------------------------------------
+++ Battery Care
Plugin: generic
Supported features: none available
+++ Battery Status: BAT1
/sys/class/power_supply/BAT1/manufacturer = NVT
/sys/class/power_supply/BAT1/model_name = Framewo
/sys/class/power_supply/BAT1/cycle_count = 3
/sys/class/power_supply/BAT1/charge_full_design = 3572 [mAh]
/sys/class/power_supply/BAT1/charge_full = 3541 [mAh]
/sys/class/power_supply/BAT1/charge_now = 1625 [mAh]
/sys/class/power_supply/BAT1/current_now = 178 [mA]
/sys/class/power_supply/BAT1/status = Discharging
/sys/class/power_supply/BAT1/charge_control_start_threshold = (not available)
/sys/class/power_supply/BAT1/charge_control_end_threshold = (not available)
Charge = 45.9 [%]
Capacity = 99.1 [%]
One thing that is still missing is the charge threshold data (the
(not available) above). There's been some work to make that
accessible in August, stay tuned? This would also make it possible
implement hysteresis support.
Ethernet expansion card
The Framework ethernet expansion card is a fancy little doodle:
"2.5Gbit/s and 10/100/1000Mbit/s Ethernet", the "clear housing lets
you peek at the RTL8156 controller that powers it". Which is another
way to say "we didn't completely finish prod on this one, so it kind
of looks like we 3D-printed this in the shop"....
The card is a little bulky, but I guess that's inevitable considering
the RJ-45 form factor when compared to the thin Framework laptop.
I have had a serious issue when trying it at first: the link LEDs
just wouldn't come up. I made a full bug report in the forum and
with upstream support, but eventually figured it out on my own. It's
(of course) a power saving issue: if you reboot the machine, the links
come up when the laptop is running the BIOS POST check and even when
the Linux kernel boots.
I first thought that the problem is likely related to the
powertop service which I run at boot time to tweak some power saving
settings.
It seems like this:
echo 'on' > '/sys/bus/usb/devices/4-2/power/control'
... is a good workaround to bring the card back online. You can even
return to power saving mode and the card will still work:
echo 'auto' > '/sys/bus/usb/devices/4-2/power/control'
Further research by Matt_Hartley from the Framework
Team found this issue in the tlp tracker that shows how the
USB_AUTOSUSPEND setting enables the power saving even if the
driver doesn't support it, which, in retrospect, just sounds like a
bad idea. To quote that issue:
By default, USB power saving is active in the kernel, but not
force-enabled for incompatible drivers. That is, devices that
support suspension will suspend, drivers that do not, will not.
So the fix is actually to uninstall tlp or disable that setting by
adding this to /etc/tlp.conf:
USB_AUTOSUSPEND=0
... but that disables auto-suspend on all USB devices, which may
hurt other power usage performance. I have found that a a
combination of:
USB_AUTOSUSPEND=1
USB_DENYLIST="0bda:8156"
and this on the kernel commandline:
usbcore.quirks=0bda:8156:k
... actually does work correctly. I now have this in my
/etc/default/grub.d/framework-tweaks.cfg file:
# net.ifnames=0: normal interface names ffs (e.g. eth0, wlan0, not wlp166
s0)
# nvme.noacpi=1: reduce SSD disk power usage (not working)
# mem_sleep_default=deep: reduce power usage during sleep (not working)
# usbcore.quirk is a workaround for the ethernet card suspend bug: https:
//guides.frame.work/Guide/Fedora+37+Installation+on+the+Framework+Laptop/
108?lang=en
GRUB_CMDLINE_LINUX="net.ifnames=0 nvme.noacpi=1 mem_sleep_default=deep usbcore.quirks=0bda:8156:k"
# fix the resolution in grub for fonts to not be tiny
GRUB_GFXMODE=1024x768
Other than that, I haven't been able to max out the card because I
don't have other 2.5Gbit/s equipment at home, which is strangely
satisfying. But running against my Turris Omnia
router, I could pretty much max a gigabit fairly easily:
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 1.09 GBytes 937 Mbits/sec 238 sender
[ 5] 0.00-10.00 sec 1.09 GBytes 934 Mbits/sec receiver
The card doesn't require any proprietary firmware blobs which is
surprising. Other than the power saving issues, it just works.
In my power tests (see powerstat-wayland), the Ethernet card seems
to use about 1.6W of power idle, without link, in the above "quirky"
configuration where the card is functional but without autosuspend.
Proprietary firmware blobs
The framework does need proprietary firmware to operate. Specifically:
- the WiFi network card shipped with the DIY kit is a AX210 card that
requires a 5.19 kernel or later, and the firmware-iwlwifi non-free firmware package
- the Bluetooth adapter also loads the firmware-iwlwifi
package (untested)
- the graphics work out of the box without firmware, but certain
power management features come only with special proprietary
firmware, normally shipped in the firmware-misc-nonfree
but currently missing from the package
Note that, at the time of writing, the
latest i915 firmware from
linux-firmware has a
serious bug where loading
all the
accessible firmware results in noticeable I estimate 200-500ms lag
between the keyboard (not the mouse!) and the display. Symptoms also
include tearing and shearing of windows, it's pretty nasty.
One workaround is to delete the two affected firmware files:
cd /lib/firmware && rm adlp_guc_70.1.1.bin adlp_guc_69.0.3.bin
update-initramfs -u
You
will get the following warning during build, which is
good as
it means the problematic firmware is disabled:
W: Possible missing firmware /lib/firmware/i915/adlp_guc_69.0.3.bin for module i915
W: Possible missing firmware /lib/firmware/i915/adlp_guc_70.1.1.bin for module i915
But then it also means that critical firmware isn't loaded, which
means, among other things, a higher battery drain. I was able to move
from 8.5-10W down to the 7W range after making the firmware work
properly. This is also after turning the backlight all the way down,
as that takes a solid 2-3W in full blast.
The proper fix is to use some compositing manager. I ended up using
compton with the following systemd unit:
[Unit]
Description=start compositing manager
PartOf=graphical-session.target
ConditionHost=angela
[Service]
Type=exec
ExecStart=compton --show-all-xerrors --backend glx --vsync opengl-swc
Restart=on-failure
[Install]
RequiredBy=graphical-session.target
compton is orphaned however, so you might be tempted to use
picom instead, but in my experience the latter uses much
more power (1-2W extra,
similar experience). I also tried
compiz but it would just crash with:
anarcat@angela:~$ compiz --replace
compiz (core) - Warn: No XI2 extension
compiz (core) - Error: Another composite manager is already running on screen: 0
compiz (core) - Fatal: No manageable screens found on display :0
When running from the base session, I would get this instead:
compiz (core) - Warn: No XI2 extension
compiz (core) - Error: Couldn't load plugin 'ccp'
compiz (core) - Error: Couldn't load plugin 'ccp'
Thanks to
EmanueleRocca for figuring all that out. See also
this
discussion about power management on the Framework forum.
Note that Wayland environments do not require any special
configuration here and actually work better, see my
Wayland migration
notes for details.
Also note that the iwlwifi firmware also looks incomplete. Even with
the package installed, I get those errors in
dmesg:
[ 19.534429] Intel(R) Wireless WiFi driver for Linux
[ 19.534691] iwlwifi 0000:a6:00.0: enabling device (0000 -> 0002)
[ 19.541867] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-72.ucode (-2)
[ 19.541881] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-72.ucode (-2)
[ 19.541882] iwlwifi 0000:a6:00.0: Direct firmware load for iwlwifi-ty-a0-gf-a0-72.ucode failed with error -2
[ 19.541890] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-71.ucode (-2)
[ 19.541895] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-71.ucode (-2)
[ 19.541896] iwlwifi 0000:a6:00.0: Direct firmware load for iwlwifi-ty-a0-gf-a0-71.ucode failed with error -2
[ 19.541903] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-70.ucode (-2)
[ 19.541907] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-70.ucode (-2)
[ 19.541908] iwlwifi 0000:a6:00.0: Direct firmware load for iwlwifi-ty-a0-gf-a0-70.ucode failed with error -2
[ 19.541913] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-69.ucode (-2)
[ 19.541916] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-69.ucode (-2)
[ 19.541917] iwlwifi 0000:a6:00.0: Direct firmware load for iwlwifi-ty-a0-gf-a0-69.ucode failed with error -2
[ 19.541922] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-68.ucode (-2)
[ 19.541926] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-68.ucode (-2)
[ 19.541927] iwlwifi 0000:a6:00.0: Direct firmware load for iwlwifi-ty-a0-gf-a0-68.ucode failed with error -2
[ 19.541933] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-67.ucode (-2)
[ 19.541937] iwlwifi 0000:a6:00.0: firmware: failed to load iwlwifi-ty-a0-gf-a0-67.ucode (-2)
[ 19.541937] iwlwifi 0000:a6:00.0: Direct firmware load for iwlwifi-ty-a0-gf-a0-67.ucode failed with error -2
[ 19.544244] iwlwifi 0000:a6:00.0: firmware: direct-loading firmware iwlwifi-ty-a0-gf-a0-66.ucode
[ 19.544257] iwlwifi 0000:a6:00.0: api flags index 2 larger than supported by driver
[ 19.544270] iwlwifi 0000:a6:00.0: TLV_FW_FSEQ_VERSION: FSEQ Version: 0.63.2.1
[ 19.544523] iwlwifi 0000:a6:00.0: firmware: failed to load iwl-debug-yoyo.bin (-2)
[ 19.544528] iwlwifi 0000:a6:00.0: firmware: failed to load iwl-debug-yoyo.bin (-2)
[ 19.544530] iwlwifi 0000:a6:00.0: loaded firmware version 66.55c64978.0 ty-a0-gf-a0-66.ucode op_mode iwlmvm
Some of those are available in the latest upstream firmware package
(
iwlwifi-ty-a0-gf-a0-71.ucode,
-68, and
-67), but not all
(e.g.
iwlwifi-ty-a0-gf-a0-72.ucode is missing) . It's unclear what
those do or don't, as the WiFi seems to work well without them.
I still copied them in from the latest linux-firmware package in the
hope they would help with power management, but I did not notice a
change after loading them.
There are also multiple knobs on the
iwlwifi and
iwlmvm
drivers. The latter has a
power_schmeme setting which defaults to
2 (
balanced), setting it to
3 (
low power) could improve
battery usage as well, in theory. The
iwlwifi driver also has
power_save (defaults to disabled) and
power_level (1-5, defaults
to
1) settings. See also the output of
modinfo iwlwifi and
modinfo iwlmvm for other driver options.
Graphics acceleration
After loading the latest upstream firmware and setting up a
compositing manager (compton, above), I tested the classic
glxgears.
Running in a window gives me odd results, as the gears basically grind
to a halt:
Running synchronized to the vertical refresh. The framerate should be
approximately the same as the monitor refresh rate.
137 frames in 5.1 seconds = 26.984 FPS
27 frames in 5.4 seconds = 5.022 FPS
Ouch. 5FPS!
But interestingly, once the window is in full screen, it does hit the
monitor refresh rate:
300 frames in 5.0 seconds = 60.000 FPS
I'm not really a gamer and I'm not normally using any of that fancy
graphics acceleration stuff (except maybe my browser does?).
I installed intel-gpu-tools for the intel_gpu_top
command to confirm the GPU was engaged when doing those simulations. A
nice find. Other useful diagnostic tools include glxgears and
glxinfo (in mesa-utils) and (vainfo in vainfo).
Following to this post, I also made sure to have those settings
in my about:config in Firefox, or, in user.js:
user_pref("media.ffmpeg.vaapi.enabled", true);
Note that the guide suggests many other settings to tweak, but those
might actually be overkill, see this comment and its parents. I
did try forcing hardware acceleration by setting gfx.webrender.all
to true, but everything became choppy and weird.
The guide also mentions installing the intel-media-driver package,
but I could not find that in Debian.
The Arch wiki has, as usual, an excellent reference on hardware
acceleration in Firefox.
Chromium / Signal desktop bugs
It looks like both Chromium and Signal Desktop misbehave with my
compositor setup (compton + i3). The fix is to add a persistent
flag to Chromium. In Arch, it's conveniently in
~/.config/chromium-flags.conf but that doesn't actually work in
Debian. I had to put the flag in
/etc/chromium.d/disable-compositing, like this:
export CHROMIUM_FLAGS="$CHROMIUM_FLAGS --disable-gpu-compositing"
It's possible another one of the hundreds of flags might fix this
issue better, but I don't really have time to go through this entire,
incomplete, and unofficial list (!?!).
Signal Desktop is a similar problem, and doesn't reuse those flags
(because of course it doesn't). Instead I had to rewrite the wrapper
script in /usr/local/bin/signal-desktop to use this instead:
exec /usr/bin/flatpak run --branch=stable --arch=x86_64 org.signal.Signal --disable-gpu-compositing "$@"
This was mostly done in this Puppet commit.
I haven't figured out the root of this problem. I did try using
picom and xcompmgr; they both suffer from the same issue. Another
Debian testing user on Wayland told me they haven't seen this problem,
so hopefully this can be fixed by switching to
wayland.
Graphics card hangs
I believe I might have this bug which results in a total
graphical hang for 15-30 seconds. It's fairly rare so it's not too
disruptive, but when it does happen, it's pretty alarming.
The comments on that bug report are encouraging though: it seems this
is a bug in either mesa or the Intel graphics driver, which means many
people have this problem so it's likely to be fixed. There's actually
a merge request on mesa already (2022-12-29).
It could also be that bug because the error message I get is
actually:
Jan 20 12:49:10 angela kernel: Asynchronous wait on fence 0000:00:02.0:sway[104431]:cb0ae timed out (hint:intel_atomic_commit_ready [i915])
Jan 20 12:49:15 angela kernel: i915 0000:00:02.0: [drm] GPU HANG: ecode 12:0:00000000
Jan 20 12:49:15 angela kernel: i915 0000:00:02.0: [drm] Resetting chip for stopped heartbeat on rcs0
Jan 20 12:49:15 angela kernel: i915 0000:00:02.0: [drm] GuC firmware i915/adlp_guc_70.1.1.bin version 70.1
Jan 20 12:49:15 angela kernel: i915 0000:00:02.0: [drm] HuC firmware i915/tgl_huc_7.9.3.bin version 7.9
Jan 20 12:49:15 angela kernel: i915 0000:00:02.0: [drm] HuC authenticated
Jan 20 12:49:15 angela kernel: i915 0000:00:02.0: [drm] GuC submission enabled
Jan 20 12:49:15 angela kernel: i915 0000:00:02.0: [drm] GuC SLPC enabled
It's a solid 30 seconds graphical hang. Maybe the keyboard and
everything else keeps working. The latter bug report is quite long,
with many comments, but this one from January 2023 seems to say
that Sway 1.8 fixed the problem. There's also an earlier patch to
add an extra kernel parameter that supposedly fixes that too. There's
all sorts of other workarounds in there, for example this:
echo "options i915 enable_dc=1 enable_guc_loading=1 enable_guc_submission=1 edp_vswing=0 enable_guc=2 enable_fbc=1 enable_psr=1 disable_power_well=0" sudo tee /etc/modprobe.d/i915.conf
from this comment... So that one is unsolved, as far as the
upstream drivers are concerned, but maybe could be fixed through Sway.
Weird USB hangs / graphical glitches
I have had weird connectivity glitches better described in this
post, but basically: my USB keyboard and mice (connected over a
USB hub) drop keys, lag a lot or hang, and I get visual glitches.
The fix was to tighten the screws around the CPU on the motherboard
(!), which is, thankfully, a rather simple repair.
USB docks are hell
Note that the monitors are hooked up to angela through a USB-C /
Thunderbolt dock from Cable Matters, with the lovely name of
201053-SIL. It has issues, see this blog
post for an in-depth discussion.
Shipping details
I ordered the Framework in August 2022 and received it about a month
later, which is sooner than expected because the August batch was
late.
People (including me) expected this to have an impact on the September
batch, but it seems Framework have been able to fix the delivery
problems and keep up with the demand.
As of early 2023, their website announces that laptops ship "within 5
days". I have myself ordered a few expansion cards in November 2022,
and they shipped on the same day, arriving 3-4 days later.
The supply pipeline
There are basically 6 steps in the Framework shipping pipeline, each
(except the last) accompanied with an email notification:
- pre-order
- preparing batch
- preparing order
- payment complete
- shipping
- (received)
This comes from the crowdsourced spreadsheet, which should be
updated when the status changes here.
I was part of the "third batch" of the 12th generation laptop, which
was supposed to ship in September. It ended up arriving on my door
step on September 27th, about 33 days after ordering.
It seems current orders are not processed in "batches", but in real
time, see this blog post for details on shipping.
Shipping trivia
I don't know about the others, but my laptop shipped through no less
than four different airplane flights. Here are the hops it took:
- Taoyuan, Taiwan 2022-09-23
- Anchorage, Alaska, USA (?!) 2022-09-24
- Memphis, Tennessee, USA 2022-09-25
- Winnipeg, Manitoba, Canada (!! back the wrong way!) 2022-09-26
- Mirabel, Qu bec, Canada 2022-09-27
- Montr al, Qu bec, Canada
I can't quite figure out how to calculate exactly how much mileage
that is, but it's huge. The ride through Alaska is surprising enough
but the bounce back through Winnipeg is especially weird. I guess
the route happens that way because of Fedex shipping hubs.
There was a related oddity when I had my Purism laptop shipped: it
left from the west coast and seemed to enter on an endless, two week
long road trip across the continental US.
Other resources
- dock questions:
- mods:
- Debian installation report, has good tips on the firmware
hacks necessary
- Excellent 12th gen review from an Arch Linux user
- cool expansion port mods:
- upstream resources:
- community forum, lots of information, much support, wow!
- knowledge base
- repair guides
- Linux-specific guides
- blog (RSS)
- chat is on Discord, but bridged with Matrix, there's
talk of bridging it with IRC as well, for now there's a
handful of us in
#framework on https://libera.chat/
- GitHub organization, interesting repositories include the
Expansion Cards, Input Modules, Expansion Bay,
mainboard, EmbeddedController
 A new release 0.2.7 of our RcppSMC package arrived at
CRAN earlier today. It contains
several extensions added by team member (and former GSoC student) Ilya Zarubin since the last
release. We were a little slow to release those but one of those CRAN
emails forced our hand for a release now. The updated uninitialized
variable messages in
A new release 0.2.7 of our RcppSMC package arrived at
CRAN earlier today. It contains
several extensions added by team member (and former GSoC student) Ilya Zarubin since the last
release. We were a little slow to release those but one of those CRAN
emails forced our hand for a release now. The updated uninitialized
variable messages in 









 Holger Levsen: Welcome, David, thanks for taking the time to talk with us today. First, could you briefly tell me about yourself?
David: Sure! I m David A. Wheeler and
I work for the
Holger Levsen: Welcome, David, thanks for taking the time to talk with us today. First, could you briefly tell me about yourself?
David: Sure! I m David A. Wheeler and
I work for the 
 The eighteenth release of
The eighteenth release of  This post describes how I ve put together a simple static content server for
kubernetes clusters using a Pod with a persistent volume and multiple
containers: an sftp server to manage contents, a web server to publish them
with optional access control and another one to run scripts which need access
to the volume filesystem.
The sftp server runs using
This post describes how I ve put together a simple static content server for
kubernetes clusters using a Pod with a persistent volume and multiple
containers: an sftp server to manage contents, a web server to publish them
with optional access control and another one to run scripts which need access
to the volume filesystem.
The sftp server runs using
 In June I travelled to see Nine Inch Nails perform two nights at the
In June I travelled to see Nine Inch Nails perform two nights at the